
哈囉大家好,今天是day18,向各位報告今天的影片進度:
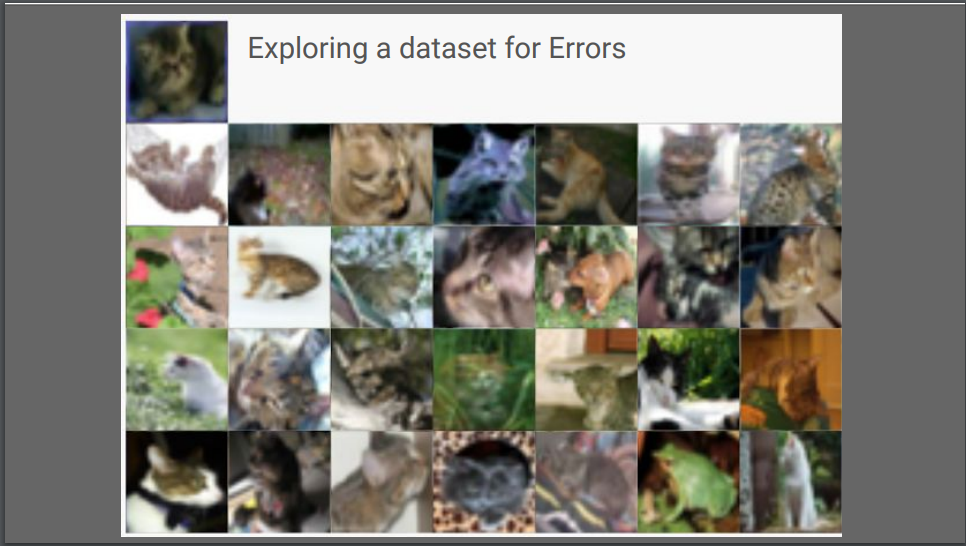
基於前面的章節,我們知道想要獲得最好的ML調適,取決於你對你資料集的了解,訓練資料的差異會造成不同的訓練結果;講者介紹Facets這個好用的資料檢視工具,他以UCI人口普查數據為例,示範facets可以計算資料的距離、以不同的label和顏色來視覺化資料;課程的最後以Cifar-10資料集為例,他發現以Cifar-10訓練出來的分類模型會將一些青蛙照片辨別成貓,用facets檢視訓練資料發現,原來問題出在一些青蛙影像的label被標記成cat,那自然訓練出的模型就走鐘了。facets是一個相當好用的工具,可以方便我們找出資料上的問題、減少人為產資料的缺失




 iThome鐵人賽
iThome鐵人賽